Wed, 04 Feb 2026
Reframing Multi-factor Authentication
In December, I was the victim of a domain hijacking attack in which Google Domains transferred control of all of my domains from my Google account to an attacker's Google account. These domains are used for my personal and business email, and all of my online accounts were associated with my email addresses at these domains. By gaining control of my domains, the attacker was able direct email sent to my domains to a mail server under his control so that he could intercept incoming email for my domains.
With control of incoming email, the attacker was able to gain control of some of the accounts registered using these email addresses. He was able to compromise those accounts that did not have multi-factor authentication enabled, requiring that, after password authentication, a one-time password sent by SMS or a generated time-based one-time password (TOTP) using a shared secret.
As a result of this attack, I have a new perspective on the value of multi-factor authentication. Re-framing how multi-factor authentication is described, in terms of possessions that one is unlikely to concurrently lose control over, makes its value clearer and provides a better way of thinking about the risks of an account being compromised.
A list of recommendations is provided at the end.
Traditional Framing of MFA
The traditional description of multi-factor authentication is a mechanism that requires two things in order to authenticate oneself:
- something the user knows
- something the user has
The "something the user knows" is typically a password. The "something the user has" is often a mobile phone, which either can receive SMS messages or has an application installed such as Google Authenticator, which stores shared keys used to generate one-time codes.
Describing of MFA in these terms is misleading for a few reasons:
- the password is no longer something the user knows
- "something the user has" is too abstract
- suggests there are only two distinct things which the user must have
It is no longer common nor recommended for users to know the password used to access each online service. Most people use tens to hundreds of services. It's not feasible to remember separate passwords for each service. Since users do not have control over how services store passwords, it's also not recommended to use the same password for multiple services. There have been numerous cases of passwords being leaked due to security compromises.
Because it's impractical to know your passwords, a password manager must be used. To make use of a password manager, you will typically want it to be available on the computers you are using regularly. These are probably your laptop/desktop and your phone. Storing your web application passwords in your Google account or your iCloud keychain, for example, keep your passwords where you need to access them.
Similarly, when you need to generate TOTP codes, it makes to do so on your phone or on your computer using an application like 1Password.
Multi-factor authentication, using a password manager and a TOTP generator therefore is better described as "something the user has" (a password manager) and "something else the user has" (a TOTP generator). If both of these are available on the same device, an attacker gaining control of one will likely gain control of the other.
So prior to the attack I underestimated the value of multi-factor authentication because I thought of it primarily in terms of what would happen if an attacker gained control of my computer. If gaining control gave them access to all of the factors needed to access an account, multi-factor authentication wasn't better than one-factor authentication.
Better Framing As Possessions
A better way to think about multi-factor authentication is:
- requiring multiple possessions, the exclusive control over which is unlikely to be lost concurrently
- understanding which possessions are fungible as authentication factors
In the domain hijacking attack, my computer wasn't compromised. None of my account passwords were compromised. None of the keys used to generate TOTP codes were compromised. What was compromised was the possession that can be described as control over incoming email (COIE), and COIE is often equivalent to a password.
Some applications make the equivalence of a password and COIE explicit. Slack, for example, will email you a one-time code to log in by default. (Authenticating using a password is also possible.)
Most other applications will allow you to reset your password if you have COIE, implicitly making the password and COIE equivalent with respect to authentication.
Equivalent Possessions
When authenticating using a service that makes a password and COIE equivalent, one of the required factors is therefore one of two possessions. If your account also has MFA configured to require a TOTP code, you need these two possessions to authenticate:
- password or COIE
- TOTP key
Some services may allow email to be used to receive one-time codes after authenticating using a password. If the service also allows resetting the password through email verification, these two factors are effectively reduced to one.
Similarly, if a service allows you to reset your password by verifying control over incoming SMS and also allows you to receive one-time codes via SMS, two-factor authentication would effectively be reduced to a single factor.
Now consider a scenario in which your passwords are stored in Google Chrome on your laptop computer and one-time passwords are sent via SMS to your phone. This ostensibly requires two distinct possessions to authenticate, your laptop and your phone. But you can inadvertently reduce this to a single possession if your SMS messages are available on your computer through iMessage or Google's Messages web client (messages.google.com), for example. (Google has recently started trying mitigate this risk by displaying messages such as "Use the Google Messages app on your phone to chat with Microsoft" when viewing messages from Microsoft or Google on the Messages web client. The browser notifications still show the full messages so this is apparently still a work-in-progress.)
Additional Considerations
Account Access Chaining
Often, one service will grant access to possessions that can be used as one or more factors to authenticate to another service. For example, if you use Gmail for email and your Google account is compromised, that grants access to the COIE possession used for authentication for many other services.
Delegated Authentication
Some services allow using another service's account to authenticate. For example, a service may allow you to sign in with your Google or Facebook account. There is a trade-off here. If you are using your Facebook to authenticate to multiple other services, and your Facebook account is compromised, the attacker can use it to gain access to all of those other services.
On the other hand, providing robust multi-factor authentication for a service is non-trivial. Facebook certainly devotes more resources to account security than many other services so it may be easier to maintain control of one Facebook account than a multitude of services with their own authentication mechanisms.
Segregation of Possessions
You may also want to segregate your possessions such that you have multiple instances of the same type of possession which are used to access different accounts. For example, you can use one email address for your bank accounts, and a different email address that's used for correspondence and to register for social media accounts or the marketing emails from your e-commerce accounts.
You could use a separate phone to generate your TOTP codes. It can be an old phone that doesn't have service that is kept at your desk. This makes access to your desk, in effect, a required possession for authentication (assuming the recovery codes that are treated as equivalent possessions are printed out and kept at the desk as well). There is a trade-off in that you will only be able to log into these accounts while at your desk, but it may be worthwhile or even desirable for certain types of accounts.
Notification
You want to be notified when one of your factors is used unexpectedly. Even if the second factor fails, you want to be notified if someone enters your password unexpected from a new location, for example.
This is analogous to having a deadbolt lock on your front door, the key to which is factor 1, along with a safe in your home to protect valuables, the code to which is factor 2 (unless you have lots of safes, you probably can keep this password in your head). It's useful to have an alarm on the front door that goes off even if a thief can't successfully break into your safe on their first try.
Recommendations
When evaluating the security of existing online accounts and when setting up accounts with new services, I offer the following suggestions.
- Enable multi-factor authentication, even on accounts that you think no
attacker would want to target
- Are your password manager and phone or authenticator applications likely to be compromised concurrently?
- Test the login process if your password was compromised through shoulder surfing, for example
- Test the "forgot your password" flow
- Pretend someone control control of our phone number through a SIM-swapping attack
- Pretend someone got control of your email inbox
- Use a password manager with long, automatically generated passwords like the one built into Chrome
- It's not necessary to change passwords regularly; a brute-force attack is unfeasible in most situations
- If pairing text messages between your phone and computer, configure the pairing to not persist indefinitely
- Consider using a different email address for important accounts like banking than you use for correspondence and marketing emails
- Consider using a separate device to generate TOTP codes for you accounts you only need to access at home
- Consider deleting email and text messages from account service providers automatically or periodically. If your mailbox compromised, these give the attacker a list of new targets.
- Consider using delegated authentication if available, using your Google or Facebook account
In addition to securing access to your accounts, you may want to take additional precautions in securing your financial accounts. In the US, you can place a fraud alert on your credit file at each of the three main credit reporting agencies. You can do this prior to being a victim of fraud. You have to renew it annually, but it notifies potential creditors to take extra precautions in verifying your identity. You can also put a freeze on your credit reports, which should prevent any new creditors from issuing new credit using your name and social security number until you lift the freeze.
To reduce the likelihood of credit card fraud, you might consider not storing your credit card details with e-commerce sites. Large sites like Amazon will require that credit cards be re-entered when shipping orders to a new address, but smaller retailers may not. As with delegated authentication, consider delegating paying by credit card to Google Pay, Apple Pay, or Amazon Pay when available.
Wed, 16 Mar 2022
Experience Buying Residential Real Estate Without a Buyer's Agent
In response to https://twitter.com/faraz_r_khan/status/1452057985501437952
I think buyers without agents are pretty rare. In Portland, a listing agent refused to present my initial offer to the seller, despite a legal obligation to do so, because it wasn't on the customary form created by the local Realtor association. I ended up buying a license for the forms, plus a license for the software to complete the forms. I resubmitted the offer, and the rest of the closing process went smoothly. The seller's agent had to a little extra work that a buyer's agent might typically do, being present for the inspection and appraisal. The sale price was about 9% below the asking price. I don't know if the listing agent reduced his commission, about $13k that was saved by not paying a buyer's agent commission.
I made an offer on another property without a buyer's agent, contingent on me being able to see it, and the listing agent refused to schedule time to show me the property. That one received multiple offers above asking so she didn't feel obliged to deal with an unusual situation, I guess.
The second property I bought without a buyer's agent was in Chicago. The seller was a real estate agent. He was fine using the purchase agreement form created by an Illinois lawywers association, which is publicly available. I believe the Chicago Realtors association has their own forms as well that aren't available to non-Realtors/lawyers. In Chicago, buyers and sellers typically use lawyers in addition to real estate agents, but close through escrow at a title company. I didn't bother hiring a lawyer for this transaction. (The lawyer we used on the purchase of our primary residence was about $800.)
I haven't sold a property without an agent, but if you have time to do showings/open houses, I don't see any reason not to. The buyer will likely have an agent, and the agent will probably expect the customary commission from you. I know someone who came to an agreement with a buyer's agent for a 1% commission.
Wed, 12 Jan 2022
A Proposal for NFTs with Actual Property Rights
I'd like to propose a project that makes use of the technology behind NFTs while solving real problems: digital concert tickets
As of early 2022, none of the popular NFT projects provide any actual property rights. The only right associated with each token is the right to transfer the token to someone else. This includes projects like the Bored Apes Yacht Club, where the cost of membership in the yacht club is comparable to lifetime membership at an actual yacht club; you get the exclusivity without access to an actual yacht club.
There are applications where being able to verify and trade property rights in unique assets could potentially be done at lower cost through the technology introduced with blockchains. I've previously argued that efficient replacements for rights licensing organizations like ASCAP and BMI, real estate title search/insurance companies, and ownership or shareholder tracking like MERS or ProxyVote are areas that could be fruitful for exploration.
Any of these would be large a undertaking so I'll propose a more tractable problem in concert ticket NFTs.
Concert tickets have characteristics and associated problems that make them well-suited for being represented as NFTs. They are
- Non-fungible: each ticket grants the right to use a specific seat in a specific venue for a specific duration
- High Value: each one trades at tens or hundreds (sometimes thousands) of dollars
- Existing solutions prone to counterfeiting
- Secondary markets are inefficient
Here's how concert tickets as NFTs would work.
- The venue (or venue's agent) selects a network on which the tickets will be issued
- The venue owner issues one Entrance Ticket as an NFT for each seat at the venue for an upcoming concert
- The venue owner either sets prices for each Entrance Ticket or auctions the tickets
- The Entrance Ticket is transferred to the buyer, completing the initial sale
- The buyer can resell the Entrance Ticket until the end of the concert
- On their way into the venue before the concert, the owner of the Entrance Ticket exchanges with the ticket collector their Entrance Ticket for a Seat Ticket
This solves a few problems with current ticketing solutions.
Buyers can verify that they are buying an authenticate ticket. They would verify that the issuer is the venue owner off-chain. The venue owner should publish the the public key of the issuer. They can simply publish it on their web site, or they could make use of a identity-linking mechanism like Keybase to link their public key to multiple identities such as a twitter profile, a domain in DNS that they own, and a website that they manage to provide buyers greater confidence that they are buying from the legitimate seller.
When one concertgoer wants to buy a ticket from a previous buyer in a secondary transaction, buyers can verify on-chain that the ticket they are buying was originally issued by the venue by verifying the identity of the original issuer.
This solves the problem with buyers potentially buying counterfeit tickets from third-party sellers using Craigslist, for example. It also can reduce the transaction costs associated with buying tickets on the secondary market through trusted intermediaries like Ticketmaster.
Venues, i.e. ticket issuers, also benefit by eliminating the possibility of counterfeiting tickets. Apart from the costs of mediating disputes when two people show up with the same ticket in the form of a bar code or two people claim the same seat number based on a printed ticket or screenshot, there will be a greater demand for tickets from buyers who know that they can resell their tickets. Therefore some of the benefit should accrue to ticket issuers in the form of higher initial ticket sale prices.
Up above, I described how Entrance Tickets are exchanged for Seat Tickets at the door. This solves the double-spend problem. A ticket holder could share their private key with another person, allowing two people to prove ownership of the same ticket if ticket ownership is simply checked at the door.
This may be minor problem, but since the tickets need to be checked at the door anyway, we can have the ticket collector and ticket holder perform a trade on-chain at the door.
The ticket holder transfers their Entrance Ticket for a Seat Ticket. The Seat Ticket is issued for the same seat at the same venue for the same duration, but is not valid for entering the venue. Now, a second holder of the private key can no longer enter the venue, but the ticket holder can still ensure show the usher which seat they own for the show.
A note about implementation:
At the moment, transaction costs on the popular networks for trading NFTs would make
secondary sales and my proposed Entrance-Ticket-for-Seat-Ticket transactions cost
prohibitive so there's work to be done. There are nascent
NFT projects on the stellar and ripple networks, where transaction settlement
time and costs are low. It may be worth exploring funding options from the Stellar Enterprise Fund or Ripple's Creator Fund.
Thu, 07 Sep 2017
Cost Accounting as a Poorly Defined Constrained Optimization Model
I recently read The Goal, a business novel that introduces the Theory of Constraints as a toolset for managing a business in order to "more money now and in the future". One of the criticisms the book makes of the way businesses are often run is that their use of cost accounting to guide decisions fails to maximize the amount of money the business can make. An alternative called throughput accounting is proposed, but after having completed The Goal, I didn't have a clear understanding of how and why cost accounting fails.
 So I bought Throughput Accounting to dig
in deeper. The book starts with a great example of a simple decision made
using cost accounting.
So I bought Throughput Accounting to dig
in deeper. The book starts with a great example of a simple decision made
using cost accounting.
A factory makes mens and womens shirts. To make a shirt, you need some raw materials, plus the labor to cut fabric and sew fabric.
- Womens shirts sell for $105. Mens shirts sell for $100.
- Raw materials for womens shirts cost $45. Raw materials for mens shirts cost $50.
- Womens shirts require 2 minutes of cutting and 15 minutes of sewing.
- Mens shirts require 10 minutes of cutting and 10 minutes of sewing.
- Market demand is such that we can sell 120 womens shirts per week at $105 and 120 mens shirts at $100.
- We only have 2,400 minutes (1 person at 40 hours per week) of cutting time, and 2,400 minutes of sewing time available each week.
- Labor costs for sewing and cutting are the same.
- Operating expenses are $10,500/week, to pay salaries, rent, etc.
| Womens | Mens | |
| Price | $105 | $100 |
| Raw Materials | $45 | $50 |
| Cutting Time | 2 minutes | 10 minutes |
| Sewing Time | 15 minutes | 10 minutes |
| Total Time | 17 minutes | 20 minutes |
| Weekly Demand | 120 shirts | 120 shirts |
Making all 120 womens shirts and 120 mens shirts requires 1,440 minutes (10 min/shirt * 120 mens shirts + 2 min/shirt * 120 womens shirts) of cutting time and 3,000 minutes (10 min/shirt * 120 mens shirts + 15 min/shirt * 120 womens shirts) of sewing time. Since we only have 2,400 minutes of sewing time available, we can't make all of the shirts. How many mens shirts and womens shirts should we make?
Gross profit for mens shirts is $50 ($100 sales price - $50 for raw materials). Gross profit for womens shirts is $60 ($105 sales price - $45 for raw materials). Mens shirts require a total of 20 minutes of labor. Womens shirts require a total of 17 minutes of labor.
Since womens shirts bring in more revenue, have a higher gross margin, and require less labor, it seems like a reasonable answer is to produce 120 womens shirts, and then as many mens shirts as we can with the remaining time we have available.
120 womens shirts take 1,800 minutes on the sewing machine, so we can make 60 mens shirts with the remaining 600 minutes available on the sewing machine. (We're not constrained by cutting.) This results in a net profit of $-300, i.e. a loss.
| Revenue | $18,600 |
| Raw Materials | $8,400 |
| Gross Margin | $10,200 |
| Operating Expense | -$10,500 |
| Net Profit | -$300 |
Throughput Accounting then explains how to calculate the amount of money (throughput) being made on the constrained resource per minute, the sewing machine, to decide how many of each product to make. But I'm going to use MiniZinc to use a contrained optimization solver to maximize net profit, which will give us the same result.
The constraints above, and the goal of trying to maximize net profit, can be translated into a MiniZinc model as follows (this would be done in a more concise manner if there were many products):
int: womens_sewing_minutes = 15; int: womens_cutting_minutes = 2; int: mens_sewing_minutes = 10; int: mens_cutting_minutes = 10; int: womens_price = 105; int: mens_price = 100; int: womens_raw_costs = 45; int: mens_raw_costs = 50; int: max_sewing_minutes = 2400; int: max_cutting_minutes = 2400; int: operating_expense = 10500; int: womens_demand = 120; int: mens_demand = 120; var 0..mens_demand: mens_produced; var 0..womens_demand: womens_produced; var int: total_sewing_minutes = womens_produced * womens_sewing_minutes + mens_produced * mens_sewing_minutes; var int: total_cutting_minutes = womens_produced * womens_cutting_minutes + mens_produced * mens_cutting_minutes; var int: revenue = womens_price * womens_produced + mens_price * mens_produced; var int: raw_materials_cost = (womens_raw_costs * womens_produced + mens_raw_costs * mens_produced); var int: gross_margin = revenue - raw_materials_cost; var int: total_cost = raw_materials_cost + operating_expense; var int: net_profit = gross_margin - operating_expense; constraint total_sewing_minutes <= max_sewing_minutes; constraint total_cutting_minutes <= max_cutting_minutes; solve maximize net_profit; output ["mens: \(mens_produced)\n", "womens: \(womens_produced)\n", "net profit: \(net_profit)\n", "total cost: \(total_cost)"];
And solving the model tells us that we should produce 120 mens shirts and 80 womens shirts for a net profit of $300, rather than a loss.
$ minizinc clothes.mzn mens: 120 womens: 80 net profit: 300 total cost: 20100 ---------- ==========
Intuitively, what's going wrong in the cost accounting solution is that we're lumping together all of the labor and not taking into consideration that the sewing machine is our bottleneck, and that we need to maximize the amount of value we're getting out of the bottleneck. Nonetheless, I struggled to translate this mistake into a MiniZinc model that also gave the wrong answer.
Below is an incorrectly defined constrained optimization model that I think reflects where we go wrong when trying to use cost accounting for decision making. The goal is changed from maximizing net profit to minimizing cost. But we don't want to just minimize cost; we could do that by producing zero shirts. We also want to produce as many shirts as we can. I modelled this as a constraint that says that producing one more mens shirt or one more womens shirt should cause us to exceed our cutting or sewing constraints.
int: womens_sewing_minutes = 15; int: womens_cutting_minutes = 2; int: mens_sewing_minutes = 10; int: mens_cutting_minutes = 10; int: womens_processing = womens_cutting_minutes + womens_sewing_minutes; int: mens_processing = mens_cutting_minutes + mens_sewing_minutes; int: womens_price = 105; int: mens_price = 100; int: womens_raw_costs = 45; int: mens_raw_costs = 50; int: max_sewing_minutes = 2400; int: max_cutting_minutes = 2400; int: operating_expense = 10500; int: womens_demand = 120; int: mens_demand = 120; var 0..mens_demand: mens_produced; var 0..womens_demand: womens_produced; var int: total_sewing_minutes = womens_produced * womens_sewing_minutes + mens_produced * mens_sewing_minutes; var int: total_cutting_minutes = womens_produced * womens_cutting_minutes + mens_produced * mens_cutting_minutes; var int: womens_revenue = womens_price * womens_produced; var int: womens_raw_materials_cost = womens_raw_costs * womens_produced; var int: womens_operating_expenses = operating_expense * womens_produced div (womens_produced + mens_produced); var int: womens_net_profit = womens_revenue - womens_raw_materials_cost - womens_operating_expenses; var int: mens_revenue = mens_price * mens_produced; var int: mens_raw_materials_cost = mens_raw_costs * mens_produced; var int: mens_operating_expenses = operating_expense * mens_produced div (womens_produced + mens_produced); var int: mens_net_profit = mens_revenue - mens_raw_materials_cost - mens_operating_expenses; var int: total_cost = womens_operating_expenses + womens_raw_materials_cost + mens_operating_expenses + mens_raw_materials_cost; var int: net_profit = womens_net_profit + mens_net_profit; constraint total_sewing_minutes <= max_sewing_minutes; constraint total_cutting_minutes <= max_cutting_minutes; % Maximize the number of items produced by ensuring that it must not be % possible to produce another item constraint ((mens_produced + 1) * mens_sewing_minutes + womens_produced * womens_sewing_minutes > max_sewing_minutes \/ (mens_produced + 1) * mens_cutting_minutes + womens_produced * womens_cutting_minutes > max_cutting_minutes) /\ (mens_produced * mens_sewing_minutes + (womens_produced + 1) * womens_sewing_minutes > max_sewing_minutes \/ mens_produced * mens_cutting_minutes + (womens_produced + 1) * womens_cutting_minutes > max_cutting_minutes); solve minimize total_cost; output ["mens: \(mens_produced)\n", "womens: \(womens_produced)\n", "net profit: \(net_profit)\n", "total cost: \(total_cost)"];
Solving this model gives us the original cost accounting result.
$ minizinc clothes-cost.mzn mens: 60 womens: 120 net profit: -300 total cost: 18900 ---------- ==========
Fri, 07 Jul 2017
Acrobat Reader 7 for Linux
Adam Langley noticed
that Adobe Reader 7 is now available for Linux. The update from version 5 has
been long overdue. The new version uses GDK rather than Motif. It has some
new features such as Save As Text, and will hopefully eliminate those annoying
warnings about a PDF requiring a newer version of Acrobat Reader (though they
always seem to be perfectly readable). Multiple PDFs are now opened within a
single application window.
Here are some Debian packages I built based on Christian Marillat's packages. I'm sure he'll do a better job soon.
Update: Christian Marillat has added acroread packages to his testing and unstable repositories. You probably want to use those.
Cast Iron Studio 7 on Linux
There's a shell script on the IBM DeveloperWorks forum describing how to run Cast Iron Studio on Linux, but it's from 2010. This describes the steps I followed to get Cast Iron Studio 7.5 running on Linux.
Download the latest version of Cast Iron Studio, 7.5.1.0 as of 2017-07-07: http://www-01.ibm.com/support/docview.wss?uid=swg24042011
The installation file is distributed as a Windows executable self-extracting zip file. The paths within the zip file contain backslashes rather than path-independent directory delimiters so the zip file needs to be fixed up before extracting it.
Use Info-ZIP's zip to strip the self-extracting stub from the zip file and to fix the structure:
$ zip -F -J 7.5.1.0-WS-WCI-20160324-1342_H11_64.studio.exe --out castiron.zip
Then use 7z's rename function to convert the backslashes to slashes within the archive.
$ 7z rn castiron.zip $(7z l castiron.zip | grep '\\' | awk '{ print $6, gensub(/\\/, "/", "g", $6); }' | paste -s)
Now you can unzip castiron.zip.
Finally, here's the modified version of the shell script I found above used to start Cast Iron Studio. Put it in the directory where you unzipped castiron.zip.
#!/bin/bash # Tell Java that the window manager is LG3D to avoid grey window /usr/bin/wmname LG3D THIS=$(readlink -f $0) DIST_HOME=$(dirname "$THIS") cd "$DIST_HOME" LIB_PATH="" LIB_PATH=$LIB_PATH:resources for f in `find plugins -type f -name '*.jar'`; do LIB_PATH=$LIB_PATH:$f done export OSGI_FRAMEWORK_JAR=org.eclipse.osgi_3.10.1.v20140909-1633.jar export SET MAIN_CLASS=org.eclipse.core.runtime.adaptor.EclipseStarter export IH_LOGGING_PROPS="resources/logging.properties" export ENDORSED="-Djava.endorsed.dirs=endorsed-lib" export KEYSTORE="-Djavax.net.ssl.keyStore=security/certs" export TRUSTSTORE="-Djavax.net.ssl.trustStore=security/cacerts" export LOGIN_CTX="-Djava.security.auth.login.config=security/httpkerb.conf" export JAAS_CONFIG="-Djava.security.auth.login.config=security/ci_jaas.config" export JVM_DIRECTIVES="-Dapplication.mode.studio=true -Djava.util.logging.config.file=$IH_LOGGING_PROPS -Dcom.sun.management.jmxremote -Djgoodies.fontSizeHints=SMALL -Djavax.xml.ws.spi.Provider=com.approuter.module.jws.ProviderImpl "-Dinstall4j.launcherId=10" -Dinstall4j.swt=false" export JAVA_HOME=/usr/lib/jvm/ibm-java-x86_64-80 "$JAVA_HOME/bin/java" -client $ENDORSED $KEYSTORE $TRUSTSTORE $LOGIN_CTX $JAAS_CONFIG $YP_AGENT $PROFILINGAGENT $JVM_DIRECTIVES -Dcom.approuter.maestro.opera.sessionFactory=com.approuter.maestro.opera.ram.RamSessionFactory -Dcom.sun.management.jmxremote -Djgoodies.fontSizeHints=SMALL -Xmx2048M -Xms512M -Xbootclasspath/p:$LIB_PATH -jar $OSGI_FRAMEWORK_JAR
Update JAVA_HOME to the path to your jvm. Performance seems to be better with the IBM jvm than the Oracle jvm.
Mon, 18 Jan 2016
Requirements in Micro-purchasing
I recently completed an 18F micro-purchase task. It turned out to be a very simple task, tweaking some CSS. I spent more time on bidding, setting up the development environment, and figuring out how to receive payment than on the actual work.
My pull request was accepted, and 18F paid me quickly, but after my changes were merged, Maya Benari pointed out that a simpler solution may have been acceptable, or perhaps even preferable.
It turns out that 18F have drafted U.S. Web Design Standards, and have already given a lot of thought to things like vertical spacing, the subject of my change.
As an independent contractor with no previous experience working with 18F, I didn't know there was a U.S. Web Design Standards document, much less its contents. Had this task been assigned to an internal staff member, they probably would have known that the page being updated should follow the standards, or that if the standards didn't adequately address the requirements for the task, that perhaps a future update to the standards should be planned.
Getting the right level of details in task requirements is often tricky. One doesn't want to spend days writing requirements for a task that can be completed in hours. But one also doesn't want what could have been an hour-long task drag on for days because the requirements were ambiguous.
When working within a long-lived team structure, there is some shared institutional knowledge that doesn't need to be made explicit in every task, like the fact that U.S. Web Design Standards exist. Usually when bringing in an outside contractor or new employee, one is starting a relationship that will last weeks, months, or years, and knowledge transfer is an expected part of the on-boarding. This investment makes sense given the size of the overall engagement.
Micro-purchasing of software development work is unique in this respect. Neither party is committing to a long-term relationship, and therefore unlikely to bear significant knowledge transfer costs. Had the acceptance criteria for my spacing fix task included compliance with the U.S. Web Design Standards, I would have had to bid more to cover the time to read and understand the document. And 18F wouldn't want to bear the cost of making me an expert on U.S. Web Design Standards if I were only going to complete a single task.
It's still early in 18F's micro-purchasing experiment, but if the experiment continues or if other organizations want to try it out, it's worth thinking about what types of tasks are best suited for micro-purchasing, and what level of detail in the requirements is optimal.
Some possible questions to ask about tasks you are considering outsourcing as micro-purchases:
- What is the value of this task to my organization?
- What estimate would an internal staff member give this task?
- What estimate would an individual outside my organization put on this task?
- Are the existing requirements sufficient for an outside developer to complete the task satisfactorily? If not, how much more work would be required to update the requirements?
As always when discussing project management, I suggest ordinal prioritization of tasks and confidence interval based estimates. If your existing tools don't support these, I recommend checking out LiquidPlanner (affiliate link).
I like the micro-purchasing model, and I hope that it succeeds and is adopted by commercial organizations.
I've gotten multiple emails from grad students doing research on Github. If you're an economics student interested in industrial organization or open source, micro-purchasing of open source software could be an interesting research project.
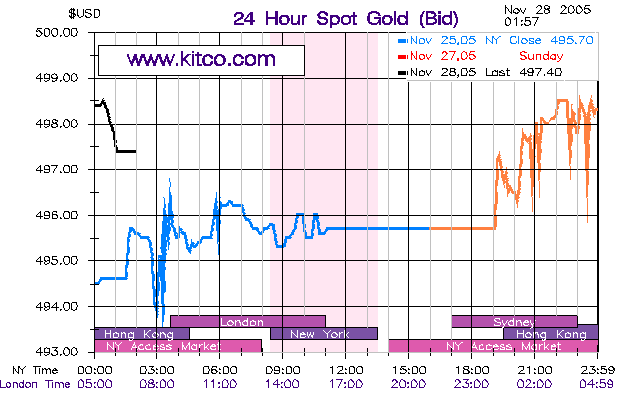
Gold Almost at $500
Gold almost hit $500/oz today.
Thu, 24 Sep 2015
Debugging Salesforce Apps with Flame Graphs
Salesforce applications can sometimes be difficult to debug. The debug log often has the information you need, but finding it isn't always easy.
For example, in a recent project, I needed to figure out why performing an action from a Visualforce page was causing more SOQL queries than expected, generating warning emails as we neared the governor limit. This was a large application that had been under development for about eight years; many different developers had been involved in various phases of its development.
As with many Salesforce applications that have been through many phases of development, it wasn't obvious how multiple triggers, workflow rules, and Process Builder flows were interrelated.
It was easy enough to figure out which SOQL queries were running multiple times by grepping the debug log, but it wasn't obvious why the method containing the query was being called repeatedly.
In researching ways to analyze call paths, I found Brendan Gregg's work on flame graphs, which visualizes call stacks with stacked bar charts. (You might also be familiar with Chrome's flame charts.)
Visualizing the call path through stacked bar charts turned out to be a good way to make sense of the Salesforce debug log.
So I created Apex Flame to visualize Salesforce debug logs using flame charts or flame graphs.
Here's an example based on the debug log generated from running one of the tests included in the Declarative Lookup Rollup Summaries tool.
You can drill in by clicking on a statement, or click on Search to highlight statements that match a string.
I'd love to get some feedback from other Salesforce developers. Try out Apex Flame, and let me know what you think.
As for the debugging issue that initially inspired the creation of Apex Flame, it turned out to be the combination of a trigger that wasn't checking whether the old and new values of a field were different, causing it to run code unnecessarily, combined with a workflow rule that was causing the trigger to be called multiple times.
Another recent case in which it turned out to be helpful was in troubleshooting
a process builder flow that was failing to update child records as expected.
The flow assumed that if the parent record is new (ISNEW()) that
it didn't have child records. It turns out this isn't necessarily true because
a trigger on the parent object can create child records, and the flow runs
after the after insert trigger. The order
of execution is documented, but visualizing the execution order made it
clear what was causing the unexpected behavior.
tech » salesforce | Permanent Link
restartd, a Process Monitor-and-Restart Daemon
Restartd is a daemon for checking your running and not running processes. It reads the /proc directory in every n secs and does a POSIX regexp on the process names. You can execute a script/program if the process is not or it is running.
In general, I don't like automated systems that restart processes. If a process dies unexpectedly, there is a problem that needs to be addressed by a human. Automatically restarting processes that randomly die makes it too easy to ignore the underlying problem.
In the case of clamd, the ClamAV daemon, I have acquiesced because I
cannot figure out why it dies randomly every month or two, and have installed
restartd.
The best thing about restartd is it's simplicity. It reads /proc/*/cmdline
every n seconds and compares each command with the list of processes defined in
it's config file. I have it configured to monitor clamd, spamd, and our
in-house Exim log-to-database utility, exidblog, and to call the
appropriate init script to restart a process if it's not running.
The current version of restartd in Debian Sarge (and Sid),
0.1.a-3, is a bit buggy in that it will fail to restart services if it is
started from an interactive session once the session is closed. Based on
suggestions
and code by Glen Turner, I've patched restartd to redirect
stdin/stdout/stderr to /dev/null, change the working directory to /, and
disassociate from the controlling terminal.
I've made the patched Debian package available for download.
